Expiration Date 4-6-2021
On April 6, 2021, we had a wildcard TLS certificate unexpectedly expire. It is embarrassing when a certificate expires, but we felt it was important to share our story here in hopes that others can also take our learnings and improve their systems. If you or your organization are using certificate monitoring, this may be a good reminder to check for gaps in those systems.
The certificate that expired was used across many internal-facing services at Epic. Too many, in fact. Despite our best efforts to monitor our certificates for expiration, we didn’t fully cover every area where certificates were being used. Following the expiration and renewal of the certificate, a series of unexpected events unfolded that extended the outage. We have more details on these in this post.
Core components like our identity and authentication systems were impacted, and these services touch many other services across our entire ecosystem. The following impacts were seen or reported:
- Epic account logins failed from any products using this form of authentication including Fortnite, Rocket League, Houseparty, Epic Online Services, or Epic Games Store
- Disconnections from live gameplay or services from all platforms
- Purchasing of items from the Epic Games Launcher failed
- Unexpected behavior in the Epic Games Launcher from content not loading to offline mode not working
- Epic Games product and marketing websites were unavailable or degraded including Unreal Engine sites
- Multiple internal tooling issues impacting Epic employees ability to resolve or manage issues
This post is intended to provide you with detailed insights about what happened, what we learned, and steps we’re going to take in the future.
What happened?
Three major sequences of events occurred:
- An expired certificate caused an outage across a large portion of internal back-end service-to-service calls and internal management tools
- Unexpected, significant increases of traffic to the Epic Games Launcher, disrupted service for the Epic Games Launcher and content distribution features
- An incorrect version of the Epic Games Store website referencing invalid artifacts and assets was deployed as part of automatic scaling, degrading the Epic Games Store experience
1) Certificate Expired

On April 6 at 12:00PM UTC a TLS certificate expired. This certificate was used for a large amount of internal-only communication across the Epic backend platform. We use TLS encryption between our back-end services for cross-service API calls and internal management tools. This certificate is for an internal DNS zone which is not public-facing.
At 12:00PM UTC traffic effectively halted between back-end systems. Six minutes later, at 12:06PM UTC, the incident was reported and our incident process started. While we had many alarms fire, we also always encourage anyone in the company to report any broadly impacting issues they see. Each incident is triaged by our 24x7 Live Ops team, who kick off our incident management process. When the first internal report arrived, our incident management tooling and process automatically spun up a Slack channel and the relevant parties were invited or paged into the incident.
At 12:12PM UTC we confirmed a certificate expired, which we believed was very likely the source of the issues, and we began the renewal process. At 12:37PM UTC the certificate was reissued and the updated certificate began rolling out to our back-end services. Over the course of the next five to 15 minutes, load balancers began automatically deploying the new certificate across internal endpoints and our service-to-service HTTPS calls recovered along with our management interfaces.
Our Live Ops team that triaged this incident was also managing the incident at this stage (communicating with employees, getting the right folks engaged), and at 12:38PM UTC, a Zoom call was spun up to coordinate people who had been collaborating in Slack. While Slack is a good communication tool, in urgent situations nothing beats real-time live communication via voice or video. Updates on the incident were being sent regularly to internal stakeholders through our tooling and process to keep everyone up to date on what was happening. At this point there were over 25 people directly engaged and working on this issue with many more observing: from Player Support, Community, Engineering, and Production across many of our different products and teams.

A graph of request counts per minute to a single microservice, with a drop for the certificate outage and an increase at the time of full recovery.
Contributing Factors
The DNS zones for this internal service-to-service communication were not actively monitored by our certificate monitoring services, an oversight by us. Our certificate monitoring services key off entire DNS namespaces, not on individual endpoints or certificates, and the configuration for this internal zone was missing. We have since moved this zone to our newer monitoring solution that addresses this gap. Prior to this incident, we had also begun a project to enable and configure AWS Config globally across our many accounts. With this setup globally we can easily add an AWS config rule enabling defense-in-depth alarming for certificate expiration.
Automatic renewals were not enabled for this internal certificate, and the work needed to accomplish this had not been prioritized when identified earlier this year. We have the appropriate systems and services in place to facilitate automatic renewal, but migrating to use these features was not completed in advance of this incident. With our existing monitoring systems, we believed that we were more protected than we actually were from the dangers of certificate expiration. We will be working on moving this certificate and others to automated renewals. In the interim, we have completed a manual audit of all of our certificates.
The service-to-service wildcard certificate used was installed across hundreds of different production services, and because of this, the impact was very broad. We use AWS ACM (AWS Certificate Manager) for managing this certificate, which enabled us to quickly renew and apply this certificate across hundreds of production services in minutes. The expiration issue had nothing to do with AWS ACM itself, but with our management of our own certificate. We will work on separating the blast radius of our certificates, and part of this will be updating our processes for certificate use with AWS ACM.
2) Significant traffic increases to Epic Games Launcher service
While most services recovered immediately following the certificate renewal, our Epic Games Launcher services remained effectively unavailable.
At 12:46PM UTC, following the certificate issuance, a surge in request rate overwhelmed Epic Games Launcher service, a key back-end service that supports the Epic Games Launcher client. The increased request rate was caused by unexpected retry logic in clients, only seen in failure scenarios. While we have done a lot of resiliency work in the Epic Games Launcher over the years, this case of magnification of requests was unexpected. Connection tracking limits were hit on our hosts, and packets were dropped across the fleet, making recovery more challenging even as our back-end application fleet scaled up 250%. The Epic Games Launcher services experienced a cascading failure and full outage, and recovery required limiting traffic to the back-end, then incrementally adding traffic back to the system while simultaneously increasing our connection tracking limits.
Our large footprint of Epic Games Launcher clients were generating tens of millions of connections to the Epic Games Launcher back-end service, and components of Epic Games Launcher systems degraded from the load. We needed to drain traffic to the back end to allow this to recover. While we normally have burst capacity available for this service, it did not allow the service to handle even the 28x load we observed at the start of the outage.

A graph of request counts per minute to our Epic Games Launcher back-end load balancer. Traffic grew 28x initially and the final burst at 15:12 UTC was 40x the normal rate.
While our request count was over 28x our normal, the sheer number of connections to the Epic Games Launcher back-end service exhausted the available connection tracking space, resulting in packet loss and ultimately degraded connectivity from back-end nodes. Our back-end connection load increased 3200x from our normal rate. The increase in TCP connections was significantly higher than the amount of requests.
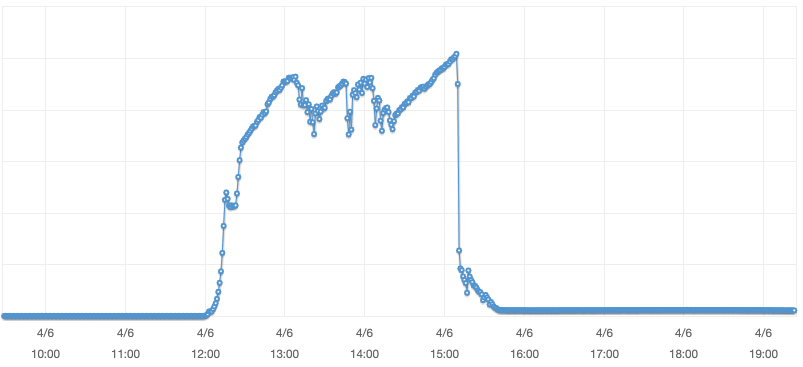
A graph of new connection counts per minute to our Epic Games Launcher back-end load balancer with a 3200x increase in connections compared to the normal peak.
Contributing Factors
The TLS certificate that expired created an outage that triggered unexpected behavior in our launcher client. Our investigation revealed our client retry was using linear retry logic instead of the exponential backoff we expected. An additional unexpected bug also caused the request pattern from millions of Epic Games Launcher clients to continuously and endlessly retry until a successful response was received. These two bugs across our client install base created an unintended and unforeseen call pattern. We were effectively DDoSed by our own clients, and we are urgently working on getting fixes for these bugs out in an Epic Games Launcher update.
An interesting contributing factor to this part of the incident is the length of the initial outage. The longer the outage lasted, the higher the probability of more clients utilizing the faulty retry logic and continually calling our back end. Had the initial outage been shorter in time, we may not have stacked up enough clients making continuous retry calls to overload the system, and only an outage of this length would have revealed this case. We will resolve this through our call pattern changes.
Our alarm for connection tracking was not well understood. This alarm fired during the incident for the Epic Games Launcher service, and while several teams are familiar with this alarm’s meaning, the alarm description and notification was not clear enough, and it was not known that this condition would cause packet loss to any connection these hosts would make, including connectivity to an internal Redis cluster. This was a stressful moment for the team investigating what could be happening as connectivity to the Redis cluster was degraded. Our caching mechanisms were suspected to be part of the cause. This later proved to be from packet loss from the connection tracking table being full, with several hundreds of thousands of connections in use. Later in the incident, we raised our connection tracking limits to over one million per node, but connection tracking increases in our infrastructure are not instant and took some time. We will work on updating our alarm to be clearer that this will cause major networking issues until resolved.
Scaling up resulted in new nodes instantly reaching connection tracking limits. Since our fleet was overloaded with connections, causing severe packet loss, we needed to reduce overall traffic to the fleet and slowly increment allowed traffic. We first attempted to use AWS WAF (Web Application Firewall) to limit to a subset of inbound traffic, however, our configuration did not limit enough traffic. This was not an issue with AWS WAF, but in our own specified ruleset. In the interest of time, we then used our AWS load balancer target weights to move some traffic, which, along with the increase of our connection tracking limits, was ultimately successful. The use of WAF in this scenario delayed our recovery of Epic Games Launcher services, but was no fault of AWS. We will develop a standard process to urgently load shed traffic in critical situations like this using AWS WAF, load balancer target weights, or other AWS technologies.
3) Epic Games Store website invalid assets
At 3:12PM UTC, with our certificate renewed and our Epic Games Launcher service recovered, we proceeded to unblock all clients calling our Epic Games Store. Due to the length of outage there were significantly more clients than normal requesting content from our Epic Games Store, which began to naturally scale up. We started assessing for any remaining impacts around 3:30PM UTC.
Everything looked normal at first, but we began to receive internal reports of layout issues and errors on the Store, which we were able to confirm and reproduce. Upon investigating the details, we noticed the web client (how a user browsing epicgames.com would interact with the Store) was trying to fetch a unique asset ID that was not present in our CDN. We checked our container versions deployed across the fleet, and they were all the same, but if that were true, how could the same application version be returning static asset values that were different?
Something wasn’t right here. This was a very confusing period of the incident, and ultimately a lot of the signals we had available (like deployed versions) turned out to be false signals. We were able to correlate the scaling of the Epic Games Store back end to an increase in 403s on our CDN, which led us down a path of investigating the new instances in more detail. Upon curling the content locally on the new instances, we discovered that the content being returned was invalid. We were able to trace this back to an unexpected container push to a new CI/CD workflow, made the day before and otherwise entirely unrelated to everything we had encountered so far during this incident. These results were still surprising, but after finally discovering this, we were able to quickly roll back the container version, terminate the invalid instances, and restore traffic.
This issue could have presented itself during any large scale up that occurred over this period, but as we normally keep plenty of headroom across the fleet, this issue did not emerge until the large scale up of the Epic Games Store occurring due to the Epic Games Launcher traffic.
Contributing Factors
The certificate outage led to Epic Games Launcher issues, which upon recovery, created a storm of requests to the Epic Games Store, which then resulted in a scale up of Epic Games Store systems. This is expected and welcome.
Our signals and data on the state of versions across our application fleet misled us into believing our fleet deployment was uniform. We have changed our versioning scheme to help prevent this misdiagnosis in the future.
A recent change to the CI/CD pipeline for Epic Games Store had a misconfiguration that updated the application artifact unexpectedly. This has been corrected with a modification to our CI/CD pipeline, reverting the unexpected changes. Our versioning scheme change will protect us if this were to happen again.
Timeline
- 12:00PM UTC - Internal certificate expired
- 12:06PM UTC - Incident reported and incident management started
- 12:15PM UTC - First customer messaging prepared
- 12:21PM UTC - Confirmation of multiple large service failures by multiple teams
- 12:25PM UTC - Confirmation the the certificate reissue process has started
- 12:37PM UTC - Certificate is confirmed to be reissued
- 12:46PM UTC - Confirmed recovery of some services
- 12:54PM UTC - Connection Tracking discovered as an issue for Epic Games Launcher service
- 1:41PM UTC - Epic Games Launcher service nodes restarted
- 3:05PM UTC - Connection Tracking limits increased for Epic Games Launcher service
- 3:12PM UTC - First signs of recovery of Epic Games Launcher service
- 3:34PM UTC - Epic Games Store web service scales up
- 3:59PM UTC - First reports of missing assets on Epic Games Store
- 4:57PM UTC - Issue with mismatched versions of Epic Games Store web service discovered
- 5:22PM UTC - Epic Games Store web service version corrected
- 5:35PM UTC - Full recovery
What’s Next?
In the sections above, we covered the scenarios that led to the surprises and ultimately the outage on April 6th. We mentioned our next steps along with our contributing factors, but we'll recap these here as well.
There is no single root cause to these issues. A myriad of factors, both technological and organizational, contributed to the events that unfolded. The scope and length of the outage helped us discover not only explicit bugs in our systems, which we will work to correct, but also previously unquestioned assumptions in some of our internal processes, especially those governing certificate management.
While we immediately moved to cover this zone with our newer certificate monitoring system, and audited all existing known certificates, we’re going to take a deeper look at any additional gaps in our certificate monitoring and add additional future-proofing, like adding AWS Config monitoring for all AWS ACM-based certificates. We'll also work to reduce the blast radius of any particular certificate.
We’re going to take a closer look at our Epic Games Launcher client call patterns and urgently fix some of the bugs we have identified as part of this, as well as improve our ability to react to situations of significantly increased traffic. With the permanent increase of our connection tracking tables for this fleet, we should be able to handle a similar amount of load without major packet loss. If you run large scale fleets this may be a good reminder to check on your connection tracking table limits and alarming if you utilize this netfilter functionality. Also, we're happy to serve as a good reminder to check the retry logic in your clients, and especially how they might behave in aggregate after a long outage.
For the Epic Games Store, we have deployed a fix that should prevent modifying a live application object, and as part of this we learned about and fixed a bug in our asset generation.
We hope this incident report provided you with additional detail on what happened on April 6th. We hope these details shed light on our learnings and improvements, and help others avoid similar issues.
Join us!
This post was written by our Reliability Engineering team with loads of help from the many other amazing engineering teams here at Epic.
Are you interested in these sorts of problems? Passionate about gaming and game services? Epic is always looking for great talent and we are hiring globally across all skill sets. If you are looking for our open positions, then visit the Epic Games Career hub.
Did this post help you or did you find this interesting? Let us know at [email protected].